Recommended Usage/Network Map
-
*EDIT - I deleted everything that used to be here, because it was wrong and it could be confusing to future users.I think I understand the basic network structure that Superdesk uses now. Because a simple architecture diagram was not available, it took me a while to figure it all out. Such an addition to the documentation would prove very useful.I will post extremely simple example architecture maps below. Superdesk Admins, please review and let me know if I've misunderstood. I think these could come in real handy to help new users who are approaching Superdesk for the first time. Feel free to re-use elsewhere (and/or to fix). If you let me know of an error, I will fix and re-post.Thank youPost edited by James Brabson at 2017-08-23 23:33:32
-
5 Comments sorted by
-
This is the simplest Superdesk installation, for very small organizations with no load or uptime requirements.(see attached)
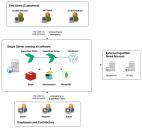 841 x 760 - 175KPost edited by James Brabson at 2017-08-23 23:15:59
841 x 760 - 175KPost edited by James Brabson at 2017-08-23 23:15:59 -
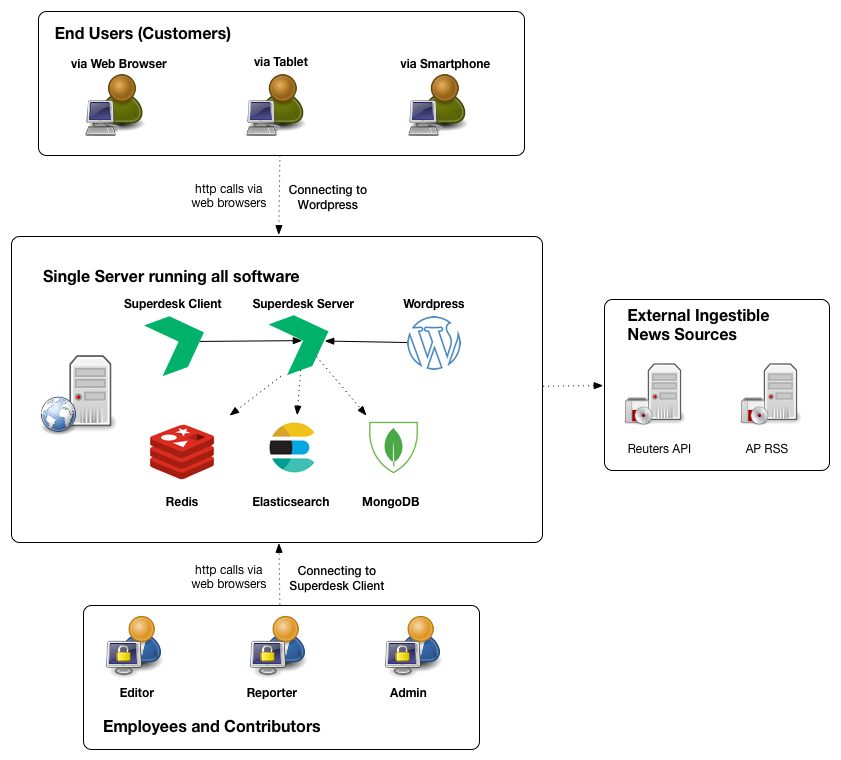
This is a more involved, but still very basic Superdesk installation, for small to medium-sized organizations that want to support a certain level of load, but who do not have absolute uptime requirements.(see attached)
 706 x 1291 - 245KPost edited by James Brabson at 2017-08-23 23:28:56
706 x 1291 - 245KPost edited by James Brabson at 2017-08-23 23:28:56 -
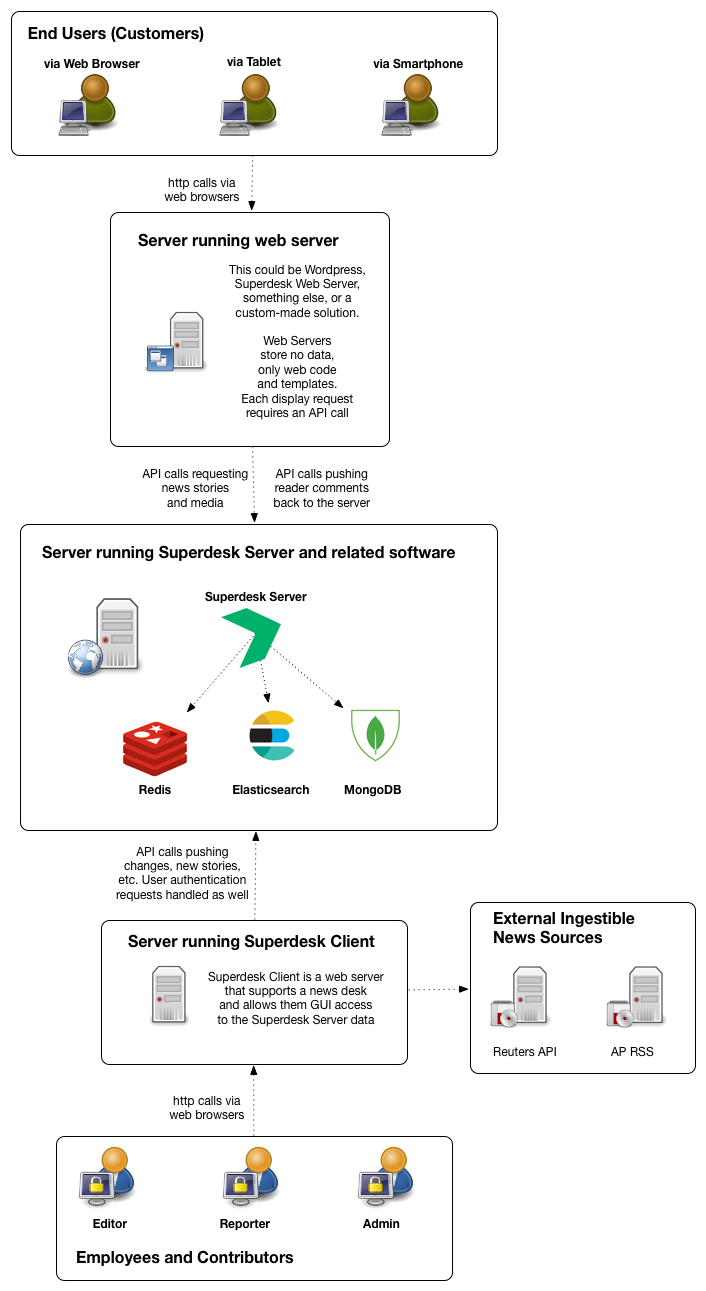
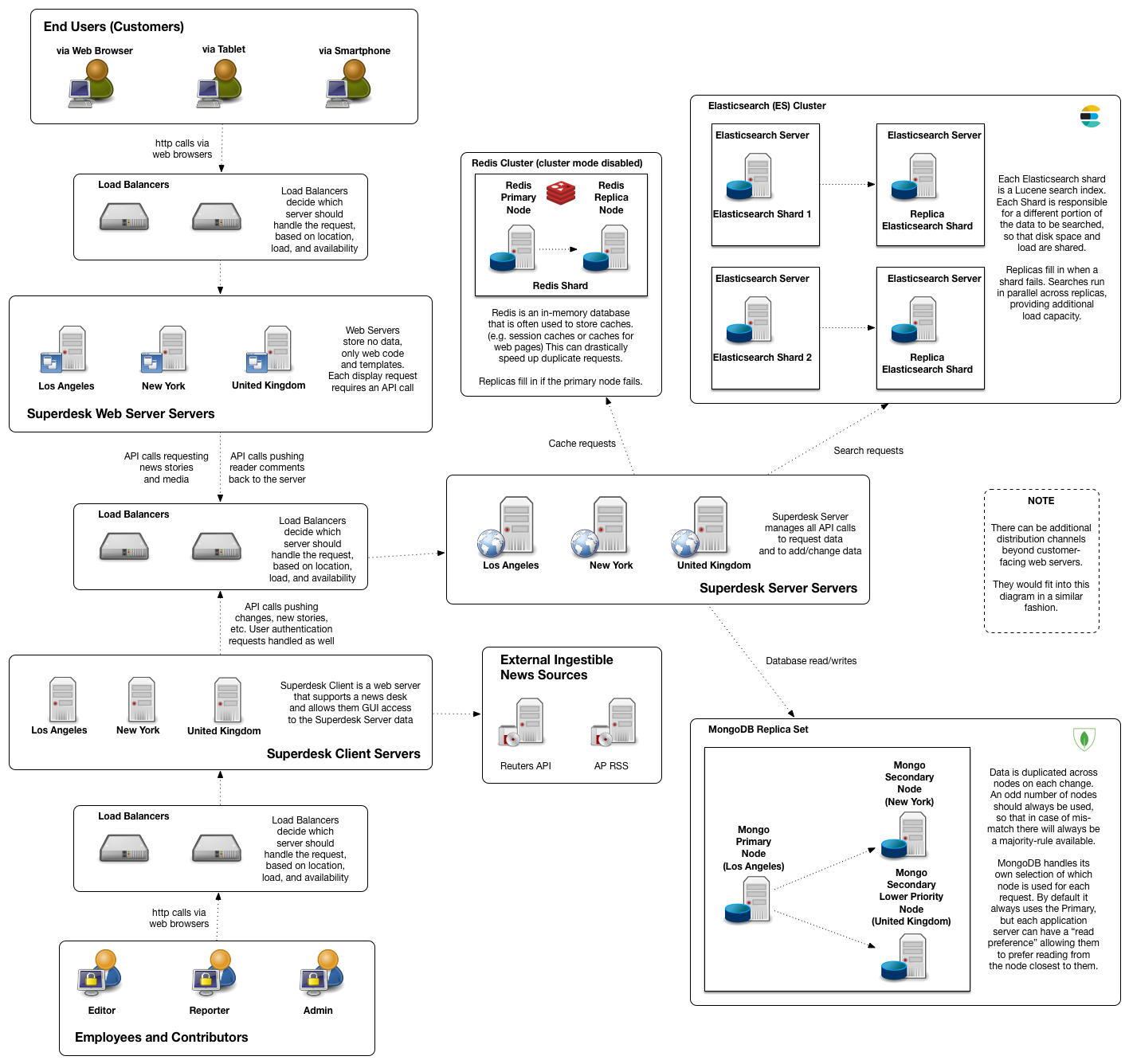
This is a full Superdesk installation, for medium to large organizations that require the ability to handle high load and high availability. I chose random geographic locations (Los Angeles, New York, and United Kingdom) to signify different regions that could remain operating while other regions went offline.This is what a 'real' Superdesk installation should probably look like.Note - The second attachment shows S3 storage in use.Note - for a truly massive organization such as the umbrella corporation that controls all worldwide branches of CNN, additional load-balancing via Mongodb Shards, Redis Clusters (with Cluster-mode enabled), and additional Elasticsearch Shards might be required, but I doubt it.(see attached)
 1417 x 1336 - 617K
1417 x 1336 - 617K 1453 x 1336 - 645KPost edited by James Brabson at 2017-08-24 00:49:08
1453 x 1336 - 645KPost edited by James Brabson at 2017-08-24 00:49:08 -
Vote Up0Vote Down
 Andrey Podshivalov
August 2017
Posts: 1,526Member, Administrator, Sourcefabric Team
Andrey Podshivalov
August 2017
Posts: 1,526Member, Administrator, Sourcefabric Team Hi James,thanks for your work!The main reason why we don't define any architecture (network map) is that each full stack superdesk installation has its own requirements and it's mostly outside superdesk software. There are tens different possible architectures for redis, mongodb. elasticseach, nginx etc. Superdesk itself can be scaled as any other classic python/celery based application. We don't want to limit any possible architecture - it's only up to you!Btw, Superdesk doesn't use Redis. It's necessary only for Celery and it means Redis can be replaced by RabbitMQ or Amazon SQSPost edited by Andrey Podshivalov at 2017-08-24 05:33:14
Hi James,thanks for your work!The main reason why we don't define any architecture (network map) is that each full stack superdesk installation has its own requirements and it's mostly outside superdesk software. There are tens different possible architectures for redis, mongodb. elasticseach, nginx etc. Superdesk itself can be scaled as any other classic python/celery based application. We don't want to limit any possible architecture - it's only up to you!Btw, Superdesk doesn't use Redis. It's necessary only for Celery and it means Redis can be replaced by RabbitMQ or Amazon SQSPost edited by Andrey Podshivalov at 2017-08-24 05:33:14 -
Thanks, Andrey.Good tip about Redis, I'll change my diagrams accordingly. (And I'll add an SMTP server, since I forgot about e-mails.)You make a very good point about the flexibility of all this architecture. For these diagrams I chose a random number of Elasticsearch shards and replicas, MongoDB nodes, Web Servers, geographic locations, etc, merely to show that a business would probably have greater than 1 of most things, to support failover in case of problem. I should have included a large note stating that whether a company runs Elasticsearch, Redis (or similar), or MongoDB on separate servers depends entirely on each company's individual use case. Whether a company uses 1 Elasticsearch shard or 10 (for example, 5 is the default assigned by Amazon when setting up a cluster), whether they use 2 superdesk server servers or they use 5, whether they position servers in 1 geographic location or 20, all that depends on their individual needs and their expected use cases.That being said, not everyone who comes here to test out Superdesk to see if it is a good fit for their organization will already be experts at all of the technologies that Superdesk uses to make itself so flexible. For example, I have experience with Lucene but not with Elasticsearch, and with NOSQL but not with MongoDB specifically. I meant for these network maps not to be a "follow this closely" guide, but instead to be an introduction to newcomers who are trying to understand the basic underlying options of Superdesk. I think many people who visit this site need to start out with a light introduction/overview such as this, to help them understand what they don't know. Too often we don't know what we don't know, and so we don't ask the right questions. That's what led me to have to spend 2 days researching, testing, and reading so I could draw these diagrams and be able to know what decisions I needed to make when designing my network. Without a rough overview like this, I had no idea just how scalable Superdesk really is.Basically, any time I spend over 4 straight hours figuring something out, I try to document what I learned so that others might benefit from my time. That's all these diagrams are meant to be -- visual aids created for myself, cleaned up and shared here in the hopes they'll be able to help others to quickly understand the rough structure and scalable nature of Superdesk.Post edited by James Brabson at 2017-08-24 15:53:03


Howdy, Stranger!
It looks like you're new here. If you want to get involved, click one of these buttons!
Categories
- All Discussions8,397
- Sourcefabric
- ↳ Announcements25
- Newscoop
- ↳ Newscoop Support2,189
- ↳ Newscoop Development722
- ↳ Newscoop Security13
- ↳ Newscoop Documentation17
- ↳ Newscoop Themes69
- Airtime
- ↳ Airtime Support3,139
- ↳ Airtime Development1,286
- ↳ Airtime Français146
- ↳ Airtime Documentation14
- ↳ Airtime Hacks102
- ↳ Promote your station!37
- ↳ Airtime Security11
- Booktype
- ↳ Booktype Support277
- ↳ Booktype Development55
- ↳ Booktype Documentation7
- Superdesk
- ↳ Superdesk Development264
- ↳ Web Publisher21
Poll
No poll attached to this discussion.Top Posters
-
 Albert FR
1978
Albert FR
1978
-
 Martin Konecny
1860
Martin Konecny
1860
-
 Andrey Podshivalov
1526
Andrey Podshivalov
1526
-
 Voisses Tech
1423
Voisses Tech
1423
-
John Chewter
899
-
Daniel James
844
-
Roger Wilco
784
-
hoerich
627
-
Paul Baranowski
389
-
Cliff Wang
339